Zuverlässigkeits-Werte für LLMs
Einführung
Halluzinationen – so nennt man KI-Antworten, die erfunden sind und nicht auf echten Begebenheiten oder Tatsachen beruhen – sind ein großes Problem bei der Verwendung von generativen Sprach-Modellen. Diese Halluzinationen kommen nicht nur in den Chats von privaten Nutzern vor, sondern können auch in kommerziellen Anwendungen zu Verwirrung und falschen Ergebnissen führen.
Gemeinsam mit der Firma Blumatix haben wir uns anhand des Beispiels von Rechnungsdaten-Extraktion eine Möglichkeit angesehen, wie LLMs sich selbst bewerten können, damit ihr BluDelta System mögliche Fehler besser erkennen kann.
Problem
Wenn LLMs in automatisierten Prozessen zum Einsatz kommen, besteht immer die oben genannte Gefahr, dass sich unerkannte Fehler in die Ergebnisse einschleichen. Bisher ist es nicht zuverlässig möglich, diese Fehler automatisch zu erkennen oder abzufangen.
Durch die von uns getestete Methode des sogenannten „Weighted Majority Voting“ (gewichtete Abstimmung) kann das LLM in inkonsistente Antworten selbst erkennen. Im Praxisbeispiel sehen wir uns dadurch an, wie Fehler in der Extraktion von Feldern wie „Nettobetrag“ oder „Umsatzsteuer-ID“ sichtbar gemacht werden können.
Unsere Umsetzung
Für die Erstellung von Zuverlässigkeits-Werten gibt es zwei Möglichkeiten:
- Abstimmung mit gewichteten Stimmen
- Analyse der Wahrscheinlichkeitsverteilung von Ausgabe-Tokens
In unserer Kooperation haben wir uns auf den ersten Ansatz fokussiert.
Der Prozess ist in drei Schritten aufgebaut:
- Überlegen und argumentieren zur Lösungsfindung
- Überlegen und argumentieren zur Findung des Zuverlässigkeits-Werts
- Ausgabe der Lösung und des Zuverlässigkeits-Werts
Die errechnete Lösung wird mit dem Zuverlässigkeits-Wert in eine gewichtete Stimme (Votes) umgewandelt.
Dieser Prozess wird für alle sogenannten Argumentationspfade (erneuter Durchlauf mit dem gleichen Dokument) wiederholt, und die Ausgaben gespeichert. Die Lösung, welche die meisten gewichteten Stimmen erhält, wird als korrekt angesehen.
Die Mischung aus häufiger Antwort und hoher selbst zugewiesener Zuverlässigkeit erhöht die Chance gegenüber einmaliger Nachfrage, dass die Antwort korrekt ist.
Untenstehend ein Beispiel: Die Kreise bilden die Antworten, die Beschriftungen der Verbindungen den Zuverlässigkeits-Wert. Der höchste summierte Zuverlässigkeits-Wert wird als Antwort ausgewählt.
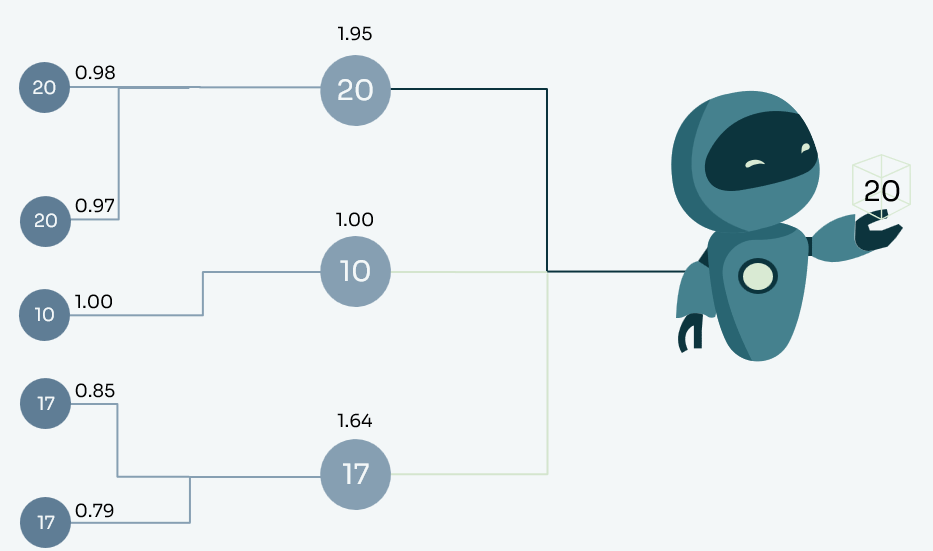
Fazit
Weighted majority voting konnte erfolgreich in zwei Teilbereichen angewendet werden. Durch die Zurverfügungstellung eines belastbaren und nachweisbaren Zuverlässigkeits-Werts an den Endkund:innen sich halten können, ist es möglich eine „Mindest-Qualität“ festzulegen. Wird zum Beispiel eine Zuverlässigkeit von >=98% gefordert (1 in 50 Antworten darf einen Fehler beinhalten), kann dies mit einer ausreichend großen Datenmenge nachweislich innerhalb einer Fehlertoleranz (Konfidenzintervall) erreicht werden.
Referenzen
- Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., … & Zhou, D. (2022). Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171.
- Yoon, D., Kim, S., Yang, S., Kim, S., Kim, S., Kim, Y., … & Seo, M. (2025). Reasoning models better express their confidence.arXiv preprint arXiv:2505.14489
- Fu, Y., Wang, X., Tian, Y., & Zhao, J. (2025). Deep think with confidence. arXiv preprint arXiv:2508.15260.
- Kang, Z., Zhao, X., & Song, D. (2025). Scalable best-of-n selection for large language models via self-certainty. arXiv preprint arXiv:2502.18581.
- Xie, J., Chen, A. S., Lee, Y., Mitchell, E., & Finn, C. (2024). Calibrating language models with adaptive temperature scaling. arXiv preprint arXiv:2409.19817.